Mark Copy algorithm
某些文档里会称copy为 #scavenge
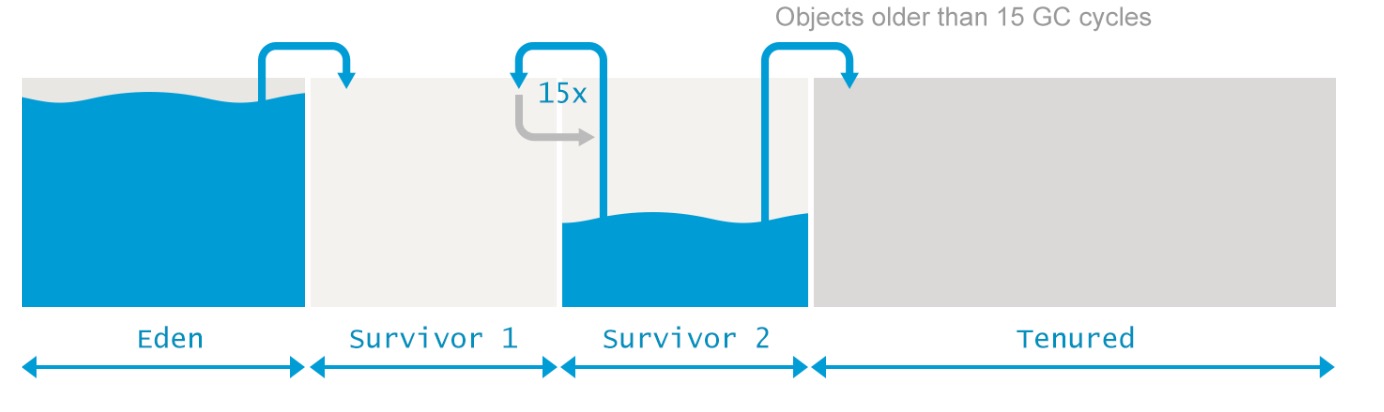
和 #mark-sweep #mark-compact 两个算法不太一样的是,在 #mark-copy 算法中,我们将内存我们需要操作的内存分成两个区域,分别称为from和to区域,但其实他们的意义和名字 并没有直接关系,因为他们两个是等价的,只使用名字做一个区分而已. 因此有的文档上也将这两个区域称为survivor 1和survivor 2,统称survivor区.

- 和 #mark-sweep 不太一样的是,本算法一边标记存活的对象,一边直接将这些存活的对象从from区复制到to区的内存前端. 该过程需要 #STW
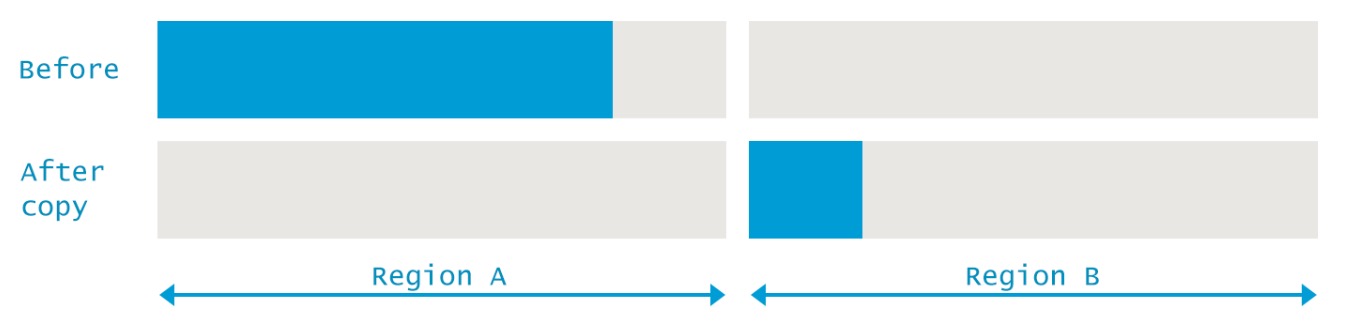
本算法的一个特点是,只需要一个阶段,一边寻找存活的对象,一边就直接把这些对象复制到另一个区域的前端即可,因此该方法的性能会比较好.复制完成后,原来的from区域不需要做清理操作,我们可以直接把整个区域都当做是已经清理完成了.
一次 #mark-copy 完成后,原来的from区变成了新的to区,原来的to区变成了新的from区.这就是为什么我们前面说这两个区域是等价的,每次操作完成后他们的相对意义就会交换一次.
尽管该算法性能比较好,也很好理解,但一个很大的问题该算法会导致我们的内存利用率不高,每次都只有50%的内存可以使用.
以上便是 #mark-copy 的基本思想.基于这个思想,很多垃圾收集器都会加上一些优化,使得内存使用率能够提高.
例如本文的第一个图片中,新生代里有一个Eden区,作为新生代区域中更加细化的分割.一般Eden和Survivor的大小比例为4:1.
由于Eden和Survivor的引入,新的策略为:
- 任何新的对象首先分配在新生代的 #eden 区中
- 一次GC后将Eden中的存活对象复制到survivor 1/from区域中
- 下一次GC的时候,就会执行本身上述的复制操作,使得存活在 #survivor 区的对象在from和to之间来回切换轮转
- 如果来回切换轮转到一定次数,则判定这个对象应该被提升至老生代
以上的这种优化算法可以提高 #utility ,利用率从50%提高到了90%.
再次强调一下,以上的假设基于一个基本的 [[分代假设]], 即新生代的对象大多数会很快失效,因此尽管80%内存都在 #eden 区,GC之后仅剩下少数的对象需要复制到 #survivor 区.